Compute In Memory Based Heterogeneous AI Silicon
Latency
Optimized
Silicon
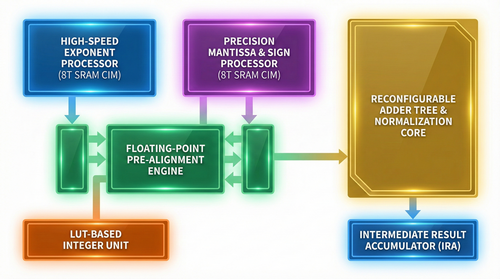
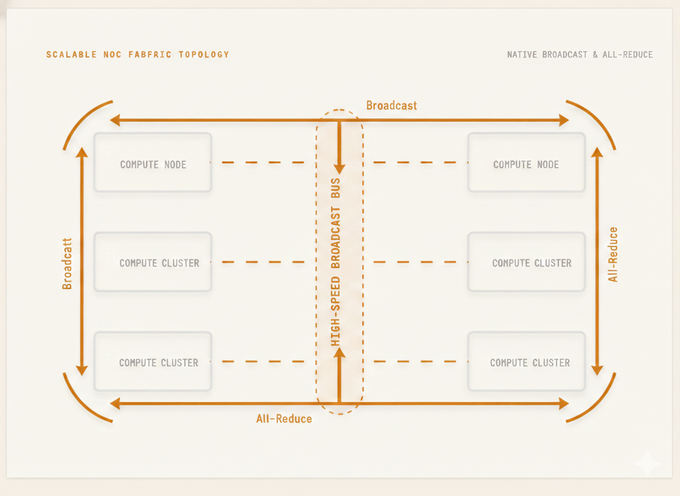
A 3D-hybrid-cube processing Unit(HCU) featuring 64 TOPS Compute In Memory with Planar Node Process for tensors and Custom RISC-V for vectors. Sub-millisecond reasoning powered by 6GB-48GB 3D DRAM.